一、背景
当我们在网上搜索、浏览网页时,搜索引擎记录下我们的搜索记录、浏览和点击记录。根据这些记录,综合网页的内容,搜索引擎推荐广告给我们、为我们定制搜索结果。同时,搜索引擎还根据我们的行为,调整它的搜索算法,提升服务质量。虽然我们感觉不到,但搜索引擎显示搜索结果页面给我们时,它所依据的是对于大量网页、用户行为数据的分析结果。
万维网的数据是海量的。至2008年,仅Google搜索引擎索引的网页就超过一万亿(10^12)个。而据估计,Google索引的页面只占所有网页的1/3。同时,有些网页背后是庞大的数据库。这些隐藏在网页背后的数据库通常被称为深度万维网(Deep Web),其规模可能是网页本身的500倍。
万维网上的应用是多样的。除了搜索,还有广告、新闻、电子商务等。这些应用所基于的数据是相同、相关、或者相似的。这些应用往往基于相同的数据平台。
正是随着WEB应用的普及和信息采集技术的进步,人类生产和收集数据的能力迅速发展,人们需要面对的数据量也日益增长。为应对这一挑战,首当其冲发展起来的信息集成技术使得当前的信息系统可以集成获得来自于不同地域、不同时间、不同应用领域的各类数据。这些数据常包含了自然观测、工业生产、产品信息、商业销售、行政管理、客户记录等类型数据中的一种或多种。它们在信息系统中所扮演的角色正在从“被管理者”向各类应用的核心转变,并已经成为企业和机构的最有价值的资产之一。这些数据的典型特点是海量、异构、半结构化或非结构化。通过网络,特别是互联网,提供基于海量数据的各类互联网服务或信息服务是信息社会发展的趋势,也同时具备了数据和应用需求这两个条件。这一发展趋势为业界和学术界提出了新的技术问题和研究问题。这类新型服务的重要特征之一是,它们都是基于海量数据处理的。在这种背景下,数据密集型计算(Data—Intensive Computing,DIC)作为新型服务的支撑技术自然引起广泛关注。
美国能源部太平洋西北国家实验室(Pacific Northwest National Laboratory)对数据密集型计算的定义为:“Data Intensive Computing is capturing, managing, analyzing, and understanding data at volumes and rates that push the frontiers of current technologies.” 其本质为能推动前沿技术发展的对海量和高速变化的数据的获取、管理、分析和理解。这包含了三层含义:
首先,它所处理的对象是数据,是围绕着数据而展开的计算。它需要处理的数据量非常巨大,且快速变化,它们往往是分布的、异构的。因此,传统的数据库管理系统不能满足其需要。
其次,"计算"包括了从数据获取到管理再到分析、理解的整个过程。因此它既不同于数据检索和数据库查询,也不同于传统的科学计算和高性能计算。它是传统数据管理、高性能计算、以及数据分析和挖掘的结合。
第三,它的目的是推动技术前沿发展,要想推动的工作是那些依赖传统的单一数据源、准静态数据库所无法实现的应用。
数据密集型计算是科学界、工业界、计算机学术界几乎同时提出的研究问题。英国《自然》杂志2008年9月4日的专刊名为“Big Data”,即“大数据”。这期杂志从互联网技术、互联网经济学、超级计算、环境科学、生物医药等多个方面介绍了海量数据所带来的技术挑战、现有解决技术,以及可以预见的未来的发展方向。这标志着数据的管理与处理在科学研究、商业活动、日常生活中已经成为一个核心问题,它已经成为互联网和计算机科学研究的最重要内容之一。

图1:据IDC报告统计,全世界一年内新产生的数据量超过270000PB,图中展示了一些重要的海量数据来源(图片来源:P.B. Gibbons在2008 Hadoop Summit上的演讲稿)
二、数据密集型计算的应用
万维网并不是数据密集型计算的仅有的应用。随着“大数据”问题的日益严重,每个个人、企业、行业内部都会出现大量的数据和依赖于数据的应用。而数据密集型计算正是满足这些应用需求的关键技术之一。典型的数据密集型计算应用包括:
万维网数据处理:如前所述,万维网作为世界上最大的“数据库”提供了各类数据,也包含了各种应用(如图2所示)。由于传统的数据处理和管理技术对于这些数据无能为力,因此万维网已经成为数据密集型计算技术最重要的推动力量。
科学研究:科学研究所产生的数据量同样是惊人的,这既包括各类实验数据,也包括论文、技术报告、项目报告、专利等科技文献。科学家和技术人员需要根据这些数据——“站在巨人的肩膀上”——进行理论研究和实验。显然,一个公共的科研服务平台是提升科研水平的关键之一。因而,科学研究也成为数据密集型计算的另一个重要应用。美国能源部太平洋西北国家实验室和美国国家自然科学基金会分别专门为此设立了科研项目,以推动科学研究的发展。
商务智能:商务智能是数据管理和数据挖掘的老问题,但是在新时代有着新的技术要求。传统的商务智能主要依赖于生产数据库、销售数据库、客服数据库等数据库和集成的数据仓库,提供智能分析服务。但是随着应用的发展,原始生产数据、企业内部技术文档、客户电子邮件等信息也将成为商务智能的分析依据。而这同样是一个海量数据上的各类复杂数据处理服务的问题。因此,商务智能和前两者一样,也是数据密集型计算的典型应用。
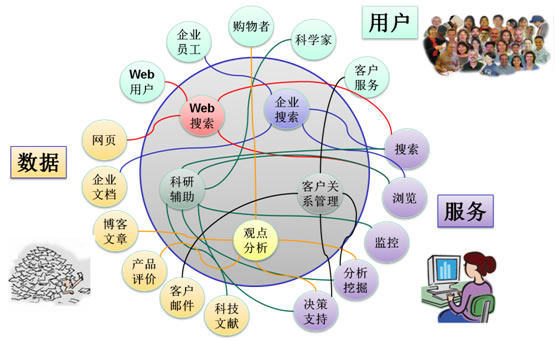
图2:一个典型的万维网数据密集型应用环境。中间的圆圈内表示应用,它们共享相似的数据、用户和服务。数据密集型计算为它们提供对于数据的各类处理服务,以满足各类用户的需要。
三、数据密集型计算的挑战
数据密集型计算对传统的、已有超过40年发展经历的数据管理技术提出了新的挑战。数据密集型计算与传统的数据管理问题相比,在应用环境、数据规模和应用需求等方面均有质的差异。它们的不同体现在数据、处理技术、以及应用提供方式这三个方面。
首先,数据密集型计算处理的是海量、快速变化、分布、异构的数据。数据量一般是TB甚至是PB级别的,因而传统的数据存储、索引技术不再适用。而地理上的分布性、模型和表示方式的异构性为数据的获取和集成造成了困难。数据的快速变化特性则要求处理必须是及时的,而传统的针对静态数据库或者数据快照的数据管理技术则无能为力。
其次,数据密集型计算中“计算”的含义是多元的。它既包括搜索、查询等传统数据处理,也包括分析和理解等“智能”处理。需要注意的是,数据密集计算所需要的数据分析和理解不仅仅是单一的数据分析或挖掘算法,这些算法必须能够在海量、分布、异构数据管理平台上得以高效实现。另一方面,数据特性决定了我们不可能为每一个数据分析和理解任务从存储和索引开始开发新的算法。因此,数据密集计算所需要的是与存储和管理平台紧密结合的、同时具有高度灵活性和定制能力的、易用的数据搜索、查询和分析工具。使用这一工具,用户可以构造复杂的数据分析甚至理解应用。
第三,由于数据密集型计算要求在海量存储、高性能计算平台上实现,因此数据密集型计算通常无法在本地提供服务。以Web服务方式提供应用接口是一种有效且自然的方式。然而和传统的高性能计算不同,用户的要求可能包括从数据获取、到预处理、再到数据的分析处理的整个过程。在这个过程中可能包括复杂的流程。因此,数据密集型计算应用的服务接口必须提供全面的流程的描述功能,并提供良好的客户机与服务器之间的基于Web服务的交互功能。
正是因为数据密集型计算中数据管理任务的这些新的特点,使得传统的数据管理技术在数据密集型计算应用中不再适用。数据密集型计算在数据管理这一问题上有两类挑战:
第一类挑战是传统数据管理技术也面临的问题,但是在数据密集型计算的环境下更为突出。首先,如何保持海量数据下数据管理和处理的可伸缩性(scalability)是一个问题。在数据密集型计算中,数据量的增长速度甚至超过了单个主存储器或硬盘容量增长的速度。因此,传统的基于集中式或者小规模分布式和并行系统的数据管理技术不再适用,相应的存储和索引技术也必须进行根本上的变革,才可能在数据量飞速增长的情况下满足应用在响应时间、吞吐量上的可伸缩性要求。
高效的、综合的数据处理技术,即融合了检索、查询、分析与挖掘的数据处理技术,是另一个挑战。数据密集型计算往往是建立在相关数据基础上的一系列应用,任意单一的数据管理技术都不适宜于这样的环境。虽然传统的数据管理技术已经从支持最初的数据库管理、查询处理演化为支持检索、查询、多维分析甚至简单的挖掘处理引擎,但是,在传统数据管理中,结构化数据查询仍然处于基础和核心地位,而其它的数据处理技术通常通过大对象(large objects)、用户自定义类型和函数、存储过程实现。其功能与性能仍然不能满足数据密集型计算的需要。
第三个挑战是系统的管理。传统的数据管理研究已经在针对单一应用的安全管理、用户管理、系统自配置等方面取得了丰富的成果。但是,数据密集型计算所服务的往往是一系列的应用,有时甚至是多租户(multi—tenant)的不同应用。此时,应用、用户、会话的管理模型将会更复杂,而多应用上的系统配置、负载均衡、性能调优需求也完全不同。
第二类挑战是传统数据管理技术已经解决或者从来没有碰到过的,但在数据密集型计算应用中涌现出的新的难题。新的事务处理需求是数据密集型计算环境下数据管理的一个根本性的问题。传统的基于ACID的事务模型是针对交易型数据管理设计的,对于包含大量分析型需求的数据密集型计算不再适合。同时,由于被广泛采用的基于锁机制的事务管理技术在大规模分布式系统中实现代价太高,因此在数据密集型计算的环境中不可能采用这些技术。所以,在数据密集型计算环境中,传统的事务处理技术无论是理论模型还是实现技术都需要重新考虑,是一个全新的问题。
其次是非结构数据处理的问题。传统的数据管理技术都是基于结构的,即使是半结构化数据处理也仍然是以结构提取为前提,辅之以专用的结构管理技术加以实现的。但在数据密集型计算应用中,数据可能是结构化的、半结构化的,或者是无结构的。而且不同应用可能需要以不同的模型处理相同的数据。如何处理“NoSQL”/“Non—Schematic”的数据是另一个全新的问题。
第三个挑战是服务模型的挑战。传统的数据管理技术所服务的是客户机/服务器模型的应用。在数据密集型计算环境中,客户与服务提供者之间的联系方式通常是互联网,它们通讯所基于的协议常常是基于HTTP的。由于带宽和稳定性的限制,加上应用所请求的服务通常是分析型的、需要对海量的数据进行处理,这就决定了必须实现高速响应、增量处理。这一需求与传统的数据管理中:“all—or—nothing”的要求是截然相反的。
最后,同样重要的是,由于通常部署在大规模分布式系统上,数据密集型计算应用必须提供良好的容错性,以减小系统维护、查询/处理重做的代价,以及提高系统的高可用性。为了获得良好的容错性,应用甚至可以接受数据处理结果在一定程度上的误差。与传统的事务处理模型相比,这也是一个根本性的区别。
四、数据密集型计算技术发展与现状
在国际上,对于数据密集计算的研究资助主要来源于三个不同的领域:科学与工程计算、电子商务,以及互联网。美国太平洋西北国家实验室正在从支持科学研究的角度对数据密集型计算开展研究,探索基于新的软硬件平台的海量数据分析技术。同时,以Amazon为代表的电子商务公司提供的系统,如EC2、S3等,已成为数据密集计算相关研究的基础平台。重要的互联网公司,则立足于自身所具有的海量Web内容和用户行为数据,研究有效管理和分析处理这些数据的技术手段。例如,Yahoo研究院专门成立了Web信息管理实验室,而微软针对搜索与广告分别成立了搜索实验室(Microsoft Search Labs)和广告中心实验室(Microsoft adCenter),Google则发表了一系列关于海量数据管理和分析处理技术的论文。电子商务和互联网具有广泛的用户基础,它们所需要的技术相比科学研究所需的更具有普遍性,需要处理更复杂、更庞大的数据,因此挑战性更大;而且互联网经济正处在一个高速发展的阶段。因此,以电子商务与互联网为背景的研究已经成为数据密集型计算的最主要的驱动力量。
当前,针对“大数据”问题,最有代表性的技术是Google文件系统(Google File System, GFS)和Map/Reduce处理模型。GFS是一种用户态分布式文件系统,而Map/Reduce则脱胎于函数程序设计(Function Programming)的编程模型。GFS和Map/Reduce具有三个共同的特点:首先,它们都是针对大规模集群设计的,以期充分利用集群良好的可伸缩性(scalability);其次,容错是它们设计时一个最重要的考虑因素,以减小大规模集群中系统维护和开发的成本;第三,它们通过使用简化的管理和处理模型来达到以上两个目的,但牺牲了一定的性能和语义正确性。GFS和Map/Reduce代表了一条新的技术路线,即基于大规模集群的数据密集型计算。基于这一路线,Google还设计、开发了相关的结构化数据管理工具BigTable以及数据分析工具Sawzall。
Google的研究工作偏向于系统底层对数据密集型计算的支持。相比而言,Yahoo的研究工作更偏重于数据密集型计算本身。Yahoo首席科学家Raghu Ramakrishnan将数据密集型计算归纳为:数据、用户、应用三者之间的交互(见图2)。由于每一种数据、每一种用户、每一类应用间的组合都要求一种不同的计算模式,因此,原有的纯粹以数据为中心的数据管理技术无法满足各类用户和各类应用的需求,无法做到数据的充分利用。Yahoo的研究工作基于一种开源软件Hadoop。基于Hadoop,Yahoo开发了针对Web数据分析的数据管理软件PNUTS (或叫Sherpa)和数据分析工具Pig。PNUTS提供了大规模集群上的结构化的数据管理工具;而Pig则提供了过程性的数据分析脚本语言的支持。
学术界同样展开了对于数据密集型计算的研究,并产生了一批重要的技术。例如,针对数据密集型计算中的数据分析处理这一最主要的任务,出现了多个分析型数据库管理系统,如CStore、MonetDB。其中,CStore和MonetDB都基于列存储(column—based storage)模型,以优化数据分析中最常见的面向列的数据统计。实验表明,采用这一存储模型,配以合适的缓存和索引技术,分析型查询的效率可以提高10到100倍,而其它查询的效率不会有明显下降(甚至有所提高)。
针对数据密集型计算中的海量数据处理这一问题,研究者开始考虑如何利用大规模集群系统所具有的可伸缩性和容错性的优势,实现高效的数据管理功能。这些研究工作可以分成2大类:基于Hadoop的技术,以及基于数据库管理系统的技术。前者以HadoopDB和Hive为代表。这些系统受到Hadoop本身在数据一致性保持、查询功能、索引功能上的限制,通常只能提供简单的查询语言,它们的本质是描述性类SQL语言到Map/Reduce过程的解释器。但这些系统也同时保持了Hadoop的容错性优点。后者以基于Amazon S3的数据库系统、Greenplum、Aster Data为代表。它们都能很好地支持复杂的数据库查询,且能够在大规模集群上进行部署。它们的设计目标为关键应用上的数据分析,因此在数据一致性和容错上都提供了较好的支持。但是,和HadoopDB和Hive相比,它们对硬件资源的消耗也更多。作为商用系统,Greenplum与Aster Data在互联网应用,特别是Web 2.0应用上(如SecondLife),得到了较广泛的使用。
数据密集型计算所需要处理的数据往往不是真正的关系型数据(或称为结构化数据)。这些数据可能是文本或者是网页、XML文档等无结构或者半结构化数据。对于这些数据的管理和处理任务也常常被称为非SQL(NoSQL)数据管理,或无模式(non—schematic)数据管理。这些技术借鉴了面向对象数据库的已有技术成果,特别是面向对象数据库对于数据模式的管理,以及对于复杂数据类型管理的技术。基于Hadoop的数据处理技术由于对数据本身的结构没有要求,因此都属于非结构数据管理技术。
数据密集型计算的服务方式与传统的基于客户机服务器(client/server)数据库管理系统截然不同。一方面,它所提供的既包括查询、检索,也包括分析服务,而用户可能并非计算机软件专业人员;另一方面,数据密集型计算平台与前端通常通过互联网连接,其带宽、稳定性、安全性存在诸多限制。由于现有数据密集型计算平台的研发大都面向企业内部,因此这仍然是一个崭新的研究课题。当前仅有的一些研究工作的共同点包括以下两点:
1.采用多维数据模型或<key, value>二元组,作为灵活的数据建模方式;
2.采用介于过程型编程语言和描述型查询语言之间的语言,如工作流描述语言,描述查询和分析任务。
虽然如此,在多租户管理、结果提交与呈现、用户交互、数据更新提交等方面,仍然缺少成熟而有效的技术。
五、数据密集型计算与云计算
数据密集型计算与“云计算”概念具有密切的关系。但是,云计算更强调系统提供服务的方式,而数据密集型计算则强调系统背后对于数据的管理与处理技术,即“计算”技术。Yahoo首席科学家Raghu Ramakrishnan认为,和传统的超级计算,即“CPU密集型计算”一样,数据密集型计算是云计算的两大支撑技术之一。
主要参考文献
[1]美国太平洋西北国家实验室数据密集计算项目主页. http://dicomputing.pnl.gov/ 2009
[2]美国自然科学基金协会CISE项目指南. http://www.nsf.gov/funding/pgm_summ.jsp?pims_id=503324&org=IIS 2009
[3] Randy E. Bryant. Data—Intensive Scalable Computing. Big Data Computing Study Group 2009.
[4] Matthias Brantner, Daniela Florescu, David A. Graf, Donald Kossmann, Tim Kraska: Building a database on S3. SIGMOD Conference 2008: 251—264
[5] 微软搜索实验室主页. http://research.microsoft.com/en—us/groups/searchlabs/ 2009
[6] 微软adCenter实验室主页. http://adlab.microsoft.com/ 2009
[7] Google实验室论文. http://research.google.com/pubs/papers.html 2009
[8] Big data: science in the petabyte era. Nature 455 8—9. 2008
[9] Randy E. Bryant. Data—Intensive Superomputing: The case of DISC. CMU Technical Report. 2007
[10] Michael Armbrust, Armando Fox, Rean Griffith, Anthony D. Joseph, Randy H. Katz, Andrew Konwinski, Gunho Lee, David A. Patterson, Ariel Rabkin, Ion Stoica and Matei Zaharia. Above the Clouds: A Berkeley View of Cloud Computing. UC Berkeley Technical Report. 2009
|


